1 任务描述
本实验利用提供的20个种类的数据集,完成KQA的任务。
2 具体实现
任务整体流程如图所示: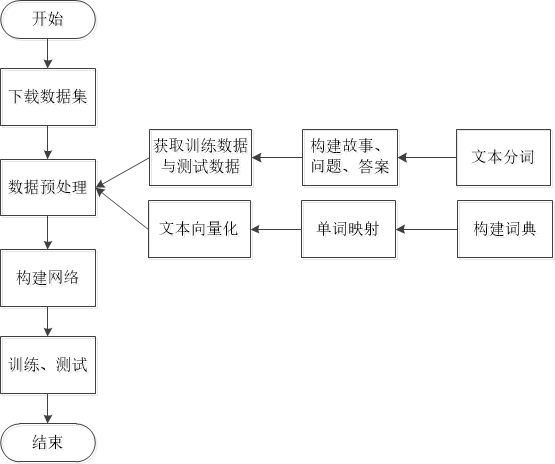
(1)引入必要的包
from __future__ import print_function
from functools import reduce
import re
import tarfile # 处理压缩文件
import numpy as np
from keras.utils import plot_model
from keras.utils.data_utils import get_file
from keras.layers.embeddings import Embedding
from keras import layers
from keras.layers import recurrent
from keras.models import Model
from keras.preprocessing.sequence import pad_sequences
(2)设置一些网络结构常量
RNN=recurrent.LSTM
EMBED_HIDDEN_SIZE=50
SENT_HIDDEN_SIZE=100
QUERY_HIDDEN_SIZE=100
BATCH_SIZE=32
EPOCHS=40
print("RNN/Embed/Sent/Query={},{},{},{}".format(RNN,EMBED_HIDDEN_SIZE,SENT_HIDDEN_SIZE,QUERY_HIDDEN_SIZE))
(3)下载数据集
数据集的获取,可以直接通过get_file()方法下载,也可以通过https://s3.amazonaws.com/text-datasets/babi_tasks_1-20_v1-2.tar.gz 网址提前下载,然后获取文件路径即可。这里对get_file()方法做简单介绍(提前下载好的文件也可以通过该方法来加载)
get_file()方法:从给定的URL中下载文件, 可以传递MD5值用于数据校验(下载后或已经缓存的数据均可)
fname: 文件名,如果指定了绝对路径/path/to/file.txt,则文件将会保存到该位置。
origin: 文件的URL地址
返回:下载后的文件地址
关于该方法的更多参数说明:http://keras-cn.readthedocs.io/en/latest/utils/#get_file
# 从网络上获取数据集
try:
path = get_file('babi-tasks-v1-2.tar.gz',
origin='https://s3.amazonaws.com/text-datasets/'
'babi_tasks_1-20_v1-2.tar.gz')
except:
print('Error downloading dataset, please download it manually:\n'
'$ wget http://www.thespermwhale.com/jaseweston/babi/tasks_1-20_v1-2'
'.tar.gz\n'
'$ mv tasks_1-20_v1-2.tar.gz ~/.keras/datasets/babi-tasks-v1-2.tar.gz')
raise
数据集中一共有20类任务数据,每一类问题又提供了两种不同数量级大小的数据集,1000个问题(默认)和10K个问题,20类问题如下:
QA1 - Single Supporting Fact
QA2 - Two Supporting Facts
QA3 - Three Supporting Facts
QA4 - Two Arg. Relations
QA5 - Three Arg. Relations
QA6 - yes/No Questions
QA7 - Counting
QA8 - Lists/Sets
QA9 - Simple Negation
QA10 - Indefinite Knowledge
QA11 - Basic Coreference
QA12 - Conjunction
QA13 - Compound Coreference
QA14 - Time Reasoning
QA15 - Basic Deduction
QA16 - Basic Induction
QA17 - Positional Reasoning
QA18 - Size Reasoning
QA19 - Path Finding
QA20 - Agent’s Motivations
打开某个数据集的txt文件,再来看看具体的数据具体内容:
1 John travelled to the hallway.
2 Mary journeyed to the bathroom.
3 Where is John? hallway 1
4 Daniel went back to the bathroom.
5 John moved to the bedroom.
6 Where is Mary? bathroom 2
7 John went to the hallway.
8 Sandra journeyed to the kitchen.
9 Where is Sandra? kitchen 8
10 Sandra travelled to the hallway.
11 John went to the garden.
12 Where is Sandra? hallway 10
13 Sandra went back to the bathroom.
14 Sandra moved to the kitchen.
15 Where is Sandra? kitchen 14
这是一个故事的具体内容(长度不一定为15),从中可以看到,每一行数据中包含了编号和文本,而文本可能是陈述句文本(这里记为事实类文本),也可以是“问句\t答案\t支撑答案的行所在编号(可能不止1个)”这种格式的(这里记为问题类文本)。
(4)获取训练集和测试集
数据集下载下来后可以解压后读入,这里使用的是tarfile模块,linux上常用tarfile模块来处理tar文件,无论tar文件是否被压缩还是仅仅被打包,都可以读取和写入tar文件,这里涉及到的方法为open()和extractfile(),
其中:
①open():除了指出打开文件的方式以外还指出了文件的压缩方式。通过filemode[:compression]的方式可以指出很多种文件模式(比如’r:gz’表示读打开,使用gzip压缩文件)
②extractfile():从tar包中提取一个子文件,但返回的是个类文件对象,可以通过read,write等方法来操作文件的内容
更多资料见:https://www.cnblogs.com/franknihao/p/6613236.html
# 构造需要的数据集格式
# Default QA1 with 1000 samples
# challenge = 'tasks_1-20_v1-2/en/qa1_single-supporting-fact_{}.txt'
# QA1 with 10,000 samples
# challenge = 'tasks_1-20_v1-2/en-10k/qa1_single-supporting-fact_{}.txt'
# QA2 with 1000 samples
challenge = 'tasks_1-20_v1-2/en/qa2_two-supporting-facts_{}.txt'
# QA2 with 10,000 samples
# challenge = 'tasks_1-20_v1-2/en-10k/qa2_two-supporting-facts_{}.txt'
with tarfile.open(path) as tar:
# 从压缩文件中获取tasks_1-20_v1-2/en/路径下的qa2_two-supporting-facts_train.txt文件,返回的是一个类文件对象,可以通过read,write等方法来操作文件的内容,此处将该对象传递给get_stories()方法
train = get_stories(tar.extractfile(challenge.format('train')))
# 同理,获取tasks_1-20_v1-2/en/路径下的qa2_two-supporting-facts_train.txt文件
test=get_stories(tar.extractfile(challenge.format("test")))
(5)数据处理过程中所用到的一些方法
在获取数据集后,需要将原始数据构建成我们能够使用的数据,其中包括,按照要求构建支撑文本,对支撑文本和问题进行分词,以及向量化操作。
①分词方法
# 分词
def tokenize(sent):
# 返回分词后所形成的列表,保留了标点符号
# 采用正则来分词,对于正则匹配的每一个字符串,如果该字符串去除左右的空白符以后不为空,则将其保留下来
return [x.strip() for x in re.split("(\w+)?",sent) if x.strip()]
②将原始数据集构建成(story,question,answer)三元组
def parse_stories(lines,only_supporting=False):
data = []
story = []
for line in lines:
# 对于读入的每一行,将其解码成utf-8格式,并去掉前后空白符
line = line.decode('utf-8').strip()
# 将该行以空格为分割符进行切割,切割一次,只需要将序号和故事内容分隔开即可。
# str.split(str="", num=string.count(str)) 其中num指定分割次数
nid, line = line.split(' ', 1)
nid = int(nid)
# 如果当前行的编号为1的话,则接下来是一个新故事的开始,首先将当前故事列表清空
if nid == 1:
story = []
# 如果这一行中包含\t,则说明是问题类文本,处理支撑文本,问题,答案,并将其加入结果list中
if '\t' in line:
# 将改行文本通过\t分割,分别获取,问题、答案、支撑行编号(可能不止一个)
q, a, supporting = line.split('\t')
# 将问题分词
q = tokenize(q)
# 根据参数选择是否保留其他不相干的文本行
substory = None
if only_supporting: # 如果only_supporting为True,则只保留支持答案的哪些文本
# Only select the related substory
# 将支撑行编号以空格符分割开,并将每个编号转为为int型
supporting = map(int, supporting.split())
# 在遇到问题类文本之前,story会将所有遇到的事实类文本都保留下来,因此,对于每一个支撑行编号,通过story[i-1]即可获取该支撑行文本
substory = [story[i - 1] for i in supporting]
else: # 如果是保留全部文本
# Provide all the substories
# 将前面所有的事实类文本都保留在substory中,作为支撑文本
substory = [x for x in story if x]
# 将处理好的支撑文本,问题,答案加入结果list
data.append((substory, q, a))
story.append('')
# 如果是事实类文本,则直接分词后加入story列表中,直到遇到问题类文本,取出里面相应的文本,作为支撑文本
else:
sent = tokenize(line)
story.append(sent)
# data中的数据格式为[(_,_,_)...]
return data
③获取数据记录
# 获取文本内容函数
def get_stories(f,only_supporting=False,max_length=None):
# 给定文件名,读取这个文件,取回故事,并且将句子转换成单个故事
# only_supporting参数决定是否只有支持答案的句子被保留下来。
data = parse_stories(f.readlines(), only_supporting=only_supporting)
# 创建一个函数
'''
reduce() 函数会对参数序列中元素进行累积。
函数将一个数据集合(链表,元组等)中的所有数据进行下列操作:用传给 reduce 中的函数 function(有两个参数)先对集合中
的第 1、2 个元素进行操作,得到的结果再与第三个数据用 function 函数运算,最后得到一个结果。
'''
# 创建一个将支撑材料列表中的元素合并成一个的匿名方法
flatten = lambda data: reduce(lambda x, y: x + y, data)
# 如果没有限制支撑材料的最大长度,或者支撑材料的最大长度小于给定的max_len,于是就将这条记录保留下来
data = [(flatten(story), q, answer) for story, q, answer in data if not max_length or len(flatten(story)) < max_length]
return data
其中创建了匿名函数,匿名函数的直观效果如下:
# flatten 方法示例
flatten = lambda data: reduce(lambda x, y: x + y, data)
story=[['a','b','c'],['d','e'],['x','y','z']]
flatten(story)
['a', 'b', 'c', 'd', 'e', 'x', 'y', 'z']
④文本向量化方法
def vectorize_stories(data,word_idx,story_maxlen,query_maxlen):
xs=[]
xqs=[]
ys=[]
# 获取每一条记录的支撑材料、问题、答案
for story,query,answer in data:
# 对于支撑材料中的每一个单词,获取其id号,结果得到的是这个支撑文本的序列模型
x=[word_idx[w] for w in story]
# 对于问题中的每一个单词,获取其id号,得到该问题的序列模型
xq=[word_idx[w] for w in query]
# y的维度应该是字典的长度+1,先初试化为0向量
y=np.zeros(len(word_idx)+1)
# 将答案所在的位置的元素值设置为1
y[word_idx[answer]]=1
# 这条记录的支撑文本序列加入结果集
xs.append(x)
# 加入处理后的问题序列
xqs.append(xq)
# 加入结果
ys.append(y)
# 将支撑文本序列和文本序列填充至最大长度,返回
return (pad_sequences(xs,maxlen=story_maxlen),pad_sequences(xqs,maxlen=query_maxlen),np.array(ys))
(6)数据向量化
# 构建词汇表
vocab=set()
## 将所以文本加起来,获取词汇表
for story,q,answer in train+test:
vocab |=set(story+q+[answer])
vocab=sorted(vocab)
vocab_size=len(vocab)+1
# 给词汇表中的每个单词建立对应的一个ID号
word_idx=dict((c,i+1) for i,c in enumerate(vocab))
print(word_idx)
{'.': 1, '?': 2, 'Daniel': 3, 'John': 4, 'Mary': 5, 'Sandra': 6, 'Where': 7, 'apple': 8, 'back': 9, 'bathroom': 10, 'bedroom': 11, 'discarded': 12, 'down': 13, 'dropped': 14, 'football': 15, 'garden': 16, 'got': 17, 'grabbed': 18, 'hallway': 19, 'is': 20, 'journeyed': 21, 'kitchen': 22, 'left': 23, 'milk': 24, 'moved': 25, 'office': 26, 'picked': 27, 'put': 28, 'the': 29, 'there': 30, 'to': 31, 'took': 32, 'travelled': 33, 'up': 34, 'went': 35}
# 获取支撑材料中单词的最大数目
story_maxlen=max(map(len,(x for x,_,_ in train+test)))
# 获取问题中单词的最大长度
query_maxlen=max(map(len,(x for _,x,_ in train+test)))
# 分别将训练集和测试集中的文本向量化
x,xq,y=vectorize_stories(train,word_idx,story_maxlen,query_maxlen)
tx,txq,ty=vectorize_stories(test,word_idx,story_maxlen,query_maxlen)
print("vocab={}".format(vocab))
print("x.shape={}".format(x.shape))
print("xq,shape={}".format(xq.shape))
print("y.shape={}".format(y.shape))
print("story_maxlen,query_maxlen={},{}".format(story_maxlen,query_maxlen))
vocab=['.', '?', 'Daniel', 'John', 'Mary', 'Sandra', 'Where', 'apple', 'back', 'bathroom', 'bedroom', 'discarded', 'down', 'dropped', 'football', 'garden', 'got', 'grabbed', 'hallway', 'is', 'journeyed', 'kitchen', 'left', 'milk', 'moved', 'office', 'picked', 'put', 'the', 'there', 'to', 'took', 'travelled', 'up', 'went']
x.shape=(1000, 552)
xq,shape=(1000, 5)
y.shape=(1000, 36)
story_maxlen,query_maxlen=552,5
这里再次用到了RepeatVector,keras.layers.core.RepeatVector(n):将输入重复n次
参数n:整数,重复的次数
输入shape:形如(nb_samples, features)的2D张量
输出shape:形如(nb_samples, n, features)的3D张量
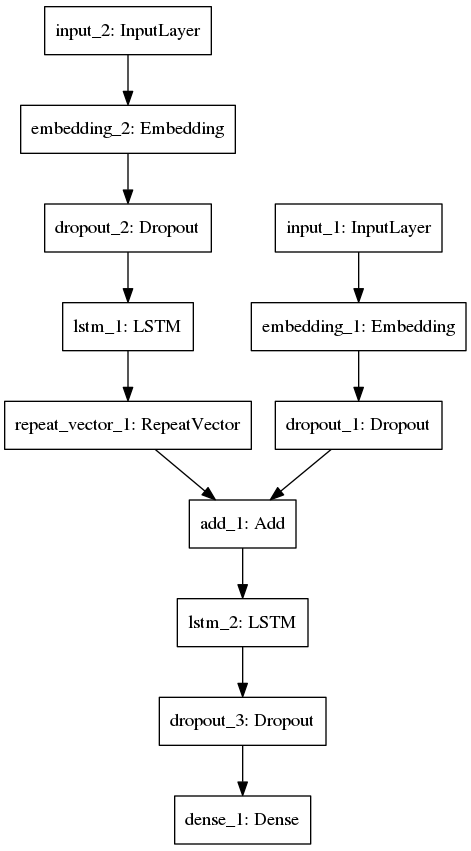
(7)搭建网络结构
print("Build model...")
# 第一个输入层,用于处理的支撑材料文本向量
sentence=layers.Input(shape=(story_maxlen,),dtype="int32")
encoded_sentence=layers.Embedding(vocab_size,EMBED_HIDDEN_SIZE)(sentence)
encoded_sentence=layers.Dropout(0.3)(encoded_sentence)
# 第二个输入层,用于处理问题文本向量
question=layers.Input(shape=(query_maxlen,),dtype="int32")
encoded_question=layers.Embedding(vocab_size,EMBED_HIDDEN_SIZE)(question)
encoded_question=layers.Dropout(0.3)(encoded_question)
encoded_question=RNN(EMBED_HIDDEN_SIZE)(encoded_question)
# 重复向量
encoded_question=layers.RepeatVector(story_maxlen)(encoded_question)
# 将两个经过处理后的输入合并
merged=layers.add([encoded_sentence,encoded_question])
merged=RNN(EMBED_HIDDEN_SIZE)(merged)
merged=layers.Dropout(0.3)(merged)
preds=layers.Dense(vocab_size,activation="softmax")(merged)
model=Model([sentence,question],preds)
model.compile(optimizer="adam",loss='categorical_crossentropy',metrics=['accuracy'])
print("Training")
model.fit([x,xq],y,batch_size=BATCH_SIZE,epochs=EPOCHS,validation_split=0.05)
loss,acc=model.evaluate([tx,txq],ty,batch_size=BATCH_SIZE)
print("Test loss / test accuracy={:.4f}/{:.4f}".format(loss,acc))
Build model...
Training
Train on 950 samples, validate on 50 samples
Epoch 1/40
950/950 [==============================] - 10s 11ms/step - loss: 2.9108 - acc: 0.1947 - val_loss: 2.1052 - val_acc: 0.0600
.
.
.
Epoch 40/40
950/950 [==============================] - 10s 10ms/step - loss: 1.6499 - acc: 0.3284 - val_loss: 1.6824 - val_acc: 0.3800
1000/1000 [==============================] - 2s 2ms/step
Test loss / test accuracy=1.7385/0.2640
(8)可视化网络结构
plot_model(model, to_file='babi_rnn_model.png')
3 小结
通过这次实验,收获也是挺多的。首先是数据的处理方式,这里将词汇映射成索引,采用了最基本的python的enumerate方法,对于词汇较少的情况来说非常快,也非常容易上手,此外将词汇映射成id号的方法还有:①利用TensorFlow提供的数据预处理接口;②利用gensim提供的接口建立字典,再将其映射成id号;③利用keras提供的数据预处理接口,同样能将文本映射成id号。接着就是tarfile对压缩文件的操作,由于之前接触linux较少,很多都还是不是很了解,通过这次实验,学到了可以直接处理压缩文件。最后就是,利用keras搭建多输入的网络结构,发现keras真的很方便,网络结构可视化也非常方便(TensorFlow绕来绕去,代码还没敲完,头都晕了_(¦3」∠)_),好啦,就酱!



